Synthetic health data facilitates collaborative medical research and health technology development
Researchers from the University of Turku and Turku University of Applied Sciences have developed ML-based/AI-driven methods to create synthetic health data. The goal is to generate privacy-preserving synthetic health useful for medical research cooperation and the development of diagnostic methods and health sector applications.
Deveoping new applications, devices or diagnostic methods for healthcare requires reliable data for testing and validation of approaches. However, the use of real health data could compromise the privacy of healthcare clients.
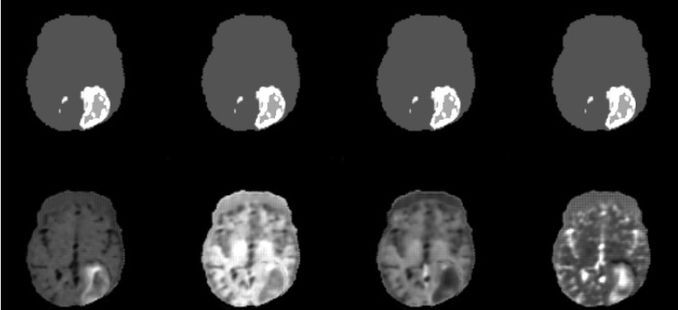
Synthetic data preserves privacy by applying statistical noise to conceal the personal data.A dataset that contains the right amount of inaccuracy makes is impossible to make reliable conclusions about the characteristics of individuals. On the other hand, one should be careful not to add too much noise, as synthetic data should still reflect the high-level phenomena observable in real data. Synthetic data can take many forms, such as tabular data, text, time series, or medical images.
The use cases for synthetic health data include applications to process body imaging data, the testing and validation of which requires reliable datasets. Data can also be used to develop predictive models for the spread of infectious diseases and to simulate the impacts of health policy interventions.
The research teams at the University of Turku and Turku University of Applied Sciences have developed AI-based methods for processing health data in a way that safeguards privacy. Two of the innovations have progressed to the patent application stage.
Whether or not use synthetic data, and how it should be done, must be considered on a case-by-case basis. Although the use of synthetic data offers plenty of opportunities, and the reliability of synthetic data is improving as the ML algorithms develop, synthetic data still needs to be treated with caution. This involves a careful evaluation of the utility and privacy requirements, and in high-risk cases, such as clinical diagnostics, decisions should always be based on real health data instead of artificial data.
– Synthetic data can also produce misleadingly accurate or significant results. In other words, things may seem clearer with the analyst's eyes than they actually are. This can lead to a false sense on reliability in terms of interpreting the results and putting them into action. In the worst case scenario, the conclusions drawn from synthetic data are not true, says Professor of Data Analytics Tapio Pahikkala from the University of Turku.
– Generating synthetic health data is a balancing act between accuracy and privacy. To be usable, the data should be realistic, but data protection and anonymity must also be ensured, says Principal Lecturer Elina Kontio, head of the Health Technology research group at Turku University of Applied Sciences.
Artificial intelligence methods for generating synthetic health data have been developed in the PRIVASA (Privacy Preserving AI for Synthetic and Anonymous Health Data) project. The aim of the project is to speed up the product development of companies by producing anonymous, individual-level health data. The AI algorithms developed in the PRIVASA project convert datasets containing sensitive information into a privacy-preserving format that supports research, development and innovation activities in the health domain.
The PRIVASA project funded by Business Finland includes the University of Turku, Turku University of Applied Sciences and VTT Technical Research Centre of Finland as well as Bayer, BCB Medical, BC Platforms, Fujitsu Finland, MVision, Perkin Elmer, Polar Electro and Yield Systems. Auria Clinical Informatics, THL and Findata have also brought their expertise to the project.
Health Technology Research Group
More information about the article
